Jakarta: NVIDIA resmi meluncurkan Blackwell Ultra, GPU terbaru yang menjadi puncak inovasi arsitektur Blackwell dan dirancang untuk mempercepat pelatihan serta inferensi AI berskala besar.
Chip ini memadukan terobosan desain silikon dengan integrasi sistem tingkat lanjut, menghadirkan performa, skalabilitas, dan efisiensi yang dibutuhkan pusat data generasi baru yang disebut “AI factory” – infrastruktur yang menjalankan layanan AI real-time dalam skala masif.
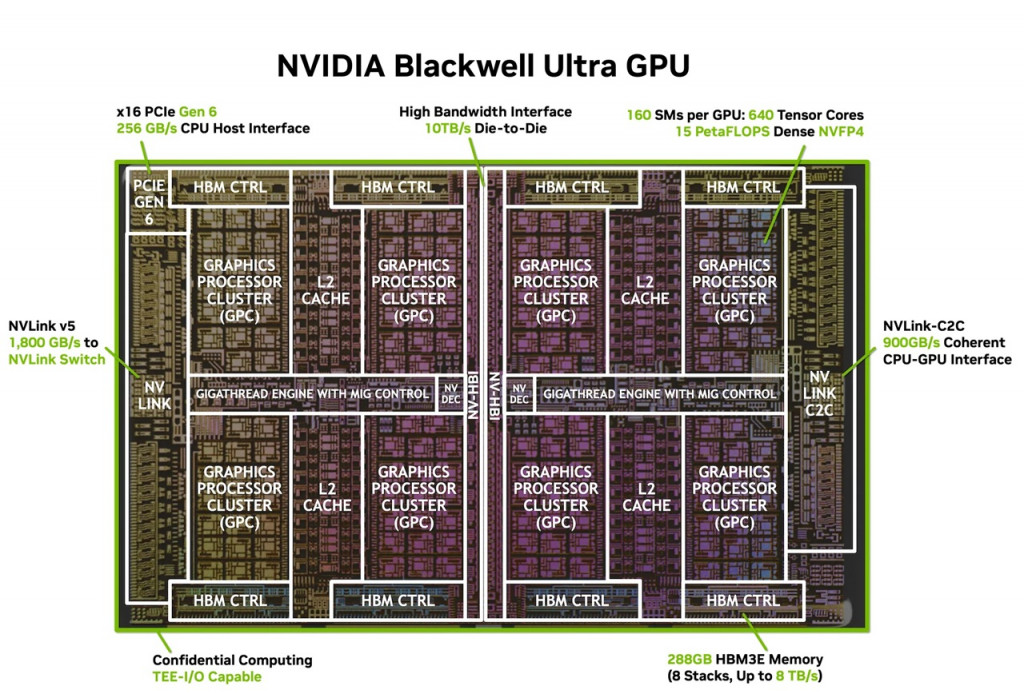
Blackwell Ultra dibangun dengan desain dual-reticle, menggabungkan dua die berukuran reticle melalui teknologi NV-HBI yang mampu menghantarkan bandwidth 10 TB/detik. Diproduksi dengan proses TSMC 4NP, GPU ini memiliki 208 miliar transistor, 2,6 kali lebih banyak dibanding NVIDIA Hopper, namun tetap diprogram sebagai satu akselerator CUDA yang utuh.
Di dalamnya terdapat 160 Streaming Multiprocessors (SM) yang menampung total 640 Tensor Core generasi kelima, menghasilkan 15 petaFLOPS komputasi NVFP4 padat—format presisi 4-bit baru yang menawarkan akurasi mendekati FP8 dengan jejak memori jauh lebih kecil.
Tensor Core generasi terbaru ini terintegrasi dengan 256 KB Tensor Memory per SM, memungkinkan data tetap dekat dengan unit komputasi untuk mengurangi lalu lintas memori eksternal.
Peningkatan throughput pada Special Function Unit (SFU) hingga dua kali lipat mempercepat perhitungan pada lapisan attention model transformer, mengurangi latensi, dan meningkatkan kecepatan pemrosesan konteks panjang yang krusial bagi model bahasa besar.
Dari sisi memori, Blackwell Ultra membawa lompatan signifikan dengan 288 GB HBM3E per GPU—3,6 kali kapasitas H100 dan 50% lebih besar dari Blackwell—serta bandwidth 8 TB/detik. Kapasitas ini memungkinkan model dengan lebih dari 300 miliar parameter dijalankan sepenuhnya di GPU tanpa perlu offloading, sekaligus memperpanjang panjang konteks dan meningkatkan efisiensi inferensi.
Konektivitasnya didukung NVLink 5 dengan bandwidth 1,8 TB/detik per GPU, NVLink-C2C untuk komunikasi CPU-GPU koheren hingga 900 GB/detik, dan PCIe Gen 6 dengan 256 GB/detik.
Semua ini dirancang untuk skala rak, seperti pada sistem GB300 NVL72 yang menggabungkan 36 Grace Blackwell Ultra Superchip dan mampu mencapai 1,1 eksaFLOPS komputasi FP4 padat, dengan output AI factory 50 kali lebih tinggi dibanding platform Hopper.
Fitur kelas enterprise meliputi Multi-Instance GPU (MIG) untuk partisi aman, confidential computing dengan Trusted Execution Environment berbasis GPU, mesin dekompresi data 800 GB/detik, serta akselerator decoding video dan gambar.
GPU ini juga mempertahankan kompatibilitas penuh dengan ekosistem CUDA, sekaligus mengoptimalkan dukungan untuk framework AI generasi baru seperti TensorRT-LLM, vLLM, dan SGLang.
Dengan kombinasi kekuatan komputasi, kapasitas memori masif, interkoneksi berkecepatan tinggi, dan fitur keamanan tingkat lanjut, NVIDIA Blackwell Ultra bukan sekadar peningkatan generasi, melainkan fondasi bagi pusat data AI masa depan. Chip ini memungkinkan model AI raksasa berjalan lebih cepat, lebih efisien, dan lebih hemat energi, sekaligus mengubah peta ekonomi inferensi di era AI berskala triliun token.
Jadikan Medcom.id sumber informasi pilihan Anda

FOLLOW US
Ikuti media sosial medcom.id dan dapatkan berbagai keuntungan















