Jakarta: Keluarga model DeepSeek-R1 yang baru-baru ini dirilis telah membawa era baru ke komunitas AI, memungkinkan pengembang menjalankan model penalaran canggih dengan kemampuan pemecahan masalah, matematika, dan kode, semuanya dari PC lokal.
Model penalaran adalah kelas baru model bahasa besar (LLM) yang menghabiskan lebih banyak waktu untuk "berpikir" dan "merenungkan" untuk mengatasi masalah yang kompleks, sambil menjelaskan langkah-langkah yang diperlukan untuk menyelesaikan suatu tugas.
Prinsip dasarnya adalah bahwa masalah apa pun dapat diselesaikan dengan pemikiran, penalaran, dan waktu yang mendalam, seperti bagaimana manusia mengatasi masalah. Dengan menghabiskan lebih banyak waktu — dan dengan demikian menghitung — pada suatu masalah, LLM dapat menghasilkan hasil yang lebih baik. Fenomena ini dikenal sebagai penskalaan waktu pengujian, dengan model secara dinamis mengalokasikan sumber daya komputasi selama inferensi untuk menalar masalah.
Model penalaran dapat meningkatkan pengalaman pengguna di PC dengan memahami kebutuhan pengguna secara mendalam, mengambil tindakan atas nama mereka, dan memungkinkan mereka memberikan umpan balik tentang proses berpikir model — membuka alur kerja agen untuk menyelesaikan tugas multi-langkah yang kompleks seperti menganalisis riset pasar, melakukan masalah matematika yang rumit, men-debug kode, dan banyak lagi.
Keluarga model DeepSeek-R1 didasarkan pada model campuran ahli (MoE) 671 miliar parameter yang besar. Model MoE terdiri dari beberapa model ahli yang lebih kecil untuk memecahkan masalah yang kompleks. Model DeepSeek lebih lanjut membagi pekerjaan dan menetapkan subtugas kepada kumpulan ahli yang lebih kecil.
DeepSeek menggunakan teknik yang disebut distilasi untuk membangun rumpun yang terdiri dari enam model yang lebih kecil — mulai dari 1,5-70 miliar parameter — dari model DeepSeek yang besar dengan parameter 671 miliar.
Kemampuan penalaran dari model parameter DeepSeek-R1 671 miliar yang lebih besar diajarkan kepada model siswa Llama dan Qwen yang lebih kecil, menghasilkan model penalaran yang kuat dan lebih kecil yang berjalan secara lokal di PC RTX AI dengan kinerja cepat.
Kecepatan inferensi sangat penting untuk kelas model penalaran baru ini. GPU GeForce RTX 50 Series, yang dibangun dengan Tensor Core generasi kelima khusus, didasarkan pada arsitektur GPU NVIDIA Blackwell yang sama yang mendorong inovasi AI terkemuka di dunia di pusat data.
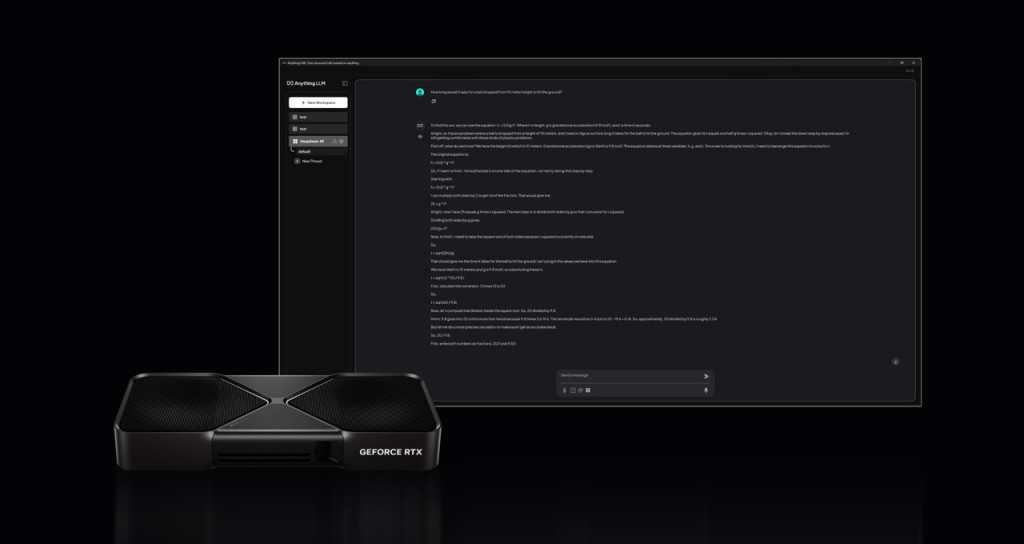
RTX sepenuhnya mempercepat DeepSeek, menawarkan kinerja inferensi maksimum pada PC. Platform RTX AI NVIDIA menawarkan pilihan alat AI, kit pengembangan perangkat lunak, dan model terluas, membuka akses ke kemampuan DeepSeek-R1 pada lebih dari 100 juta PC AI NVIDIA RTX di seluruh dunia, termasuk yang ditenagai oleh GPU GeForce RTX 50 Series.
Kekuatan DeepSeek-R1 dan RTX AI PC melalui ekosistem perangkat lunak yang luas, termasuk Llama.cpp, Ollama, LM Studio, AnythingLLM, Jan.AI, GPT4All, dan OpenWebUI, untuk inferensi. Plus, gunakan Unsloth untuk menyempurnakan model dengan data khusus.
Jadikan Medcom.id sumber informasi pilihan Anda

FOLLOW US
Ikuti media sosial medcom.id dan dapatkan berbagai keuntungan















